-
JPA - JPA의 등장Spring/JPA 2022. 3. 7. 11:05728x90반응형
JPA의 등장
웹 애플리케이션을 개발할 때 객체에 저장되어있는 데이터들을 SQL로 변환하고, RDB에 연결하여 작성한 쿼리문을 전송하여 RDB에 저장한다. 말로 했을 때는 참 쉬워 보이지만 객체와의 관계와 테이블 간의 관계에서의 차이가 존재하기 때문에 고려해야 할 사항들이 많다.
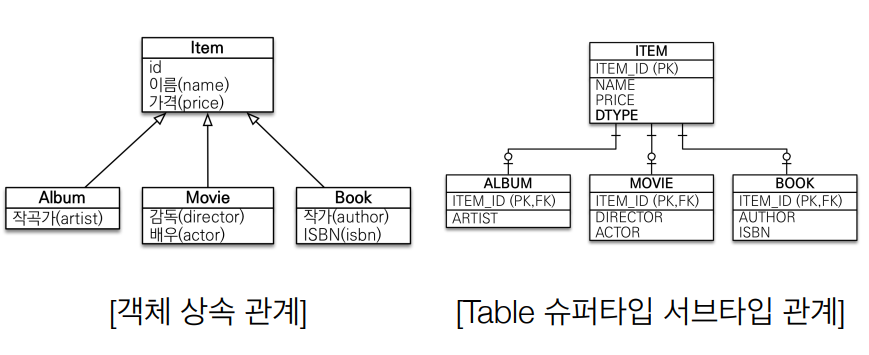
만약에 Item을 상속받는 Album 객체를 RDB에 저장한다고 생각해보자. RDB에는 ITEM 테이블과 ALBUM 테이블을 따로 관리하기 때문에 저장을 하기 위해서는 Item 객체와 Album 객체를 분리하여 각 테이블에 저장할 수 있도록 쿼리문을 작성하여 전달해야 한다. 반대는 조회는 어떨까? 조회 역시 Album을 조회하기 위해서는 ITEM 테이블과 ALBUM 테이블을 조인하여 가져온 데이터들을 각각의 객체를 생성하여 매핑시켜줘야 한다.
그런데 참조를 사용하면 어떨까?

list.add(album); // 저장 Album album = list.get(albumid); // 조회 // 부모 타입으로 조회 후 다형성 활용 Item item = list.get(albumId);위와 같이 간단하게 표현할 수 있다. 하지만 문제가 있다. 객체 연관관계는 단반향(Member는 Team을 참조, 반대 x)이지만 테이블 연관관계를 보면 양방향인 것을 알 수 있다. 이와 같은 문제를 해결하기 위해 객체를 테이블에 맞추어 모델링을 하면 다음과 같다
class Member { String id; //MEMBER_ID 컬럼 사용 Long teamId; //TEAM_ID FK 컬럼 사용 String username; //USERNAME 컬럼 사용 } class Team { Long id; //TEAM_ID PK 사용 String name; //NAME 컬럼 사용 }그런데 위와 같은 모델링은 객체지향적인 모델링이라고 생각이 안 든다. 우리가 지금까지 사용해왔던 객체와의 관계는 참조를 통해 연관관계를 맺을 수 있었다. 예를 들어 Member 객체가 참조를 통해 Team 객체를 접근하는 방법이 우리가 평소에 사용한 객체지향적인 방법이다. 따라서 객체지향적인 관점에서 해당 객체를 다시 모델링하면 다음과 같다.
class Member { String id; //MEMBER_ID 컬럼 사용 Team team; //참조로 연관관계를 맺는다. String username; //USERNAME 컬럼 사용 Team getTeam() { return team; } } class Team { Long id; //TEAM_ID PK 사용 String name; //NAME 컬럼 사용 }이로서 우리는 객체를 객체지향적인 모델링으로 RDB에 저장할 수 있다. 아래는 테이블에 맞춘 객체 모델링으로 저장할 때와 객체지향적인 모델링으로 저장할 때의 비교이다.

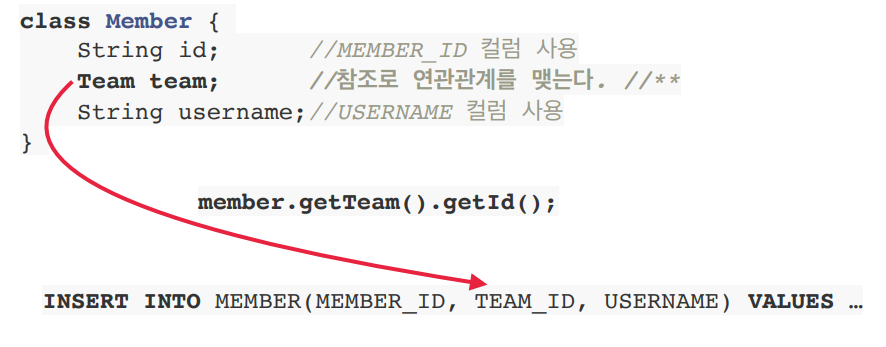
그런데 만약에 조회해온다면 어떻게 될까? MEMBER와 TEAM을 조인하여 가져온 다음에 각각에 객체에 관련 정보를 직접 넣어줘야 한다.
SELECT M.*, T.* FROM MEMBER M JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID public Member find(String memberId) { //SQL 실행 ... Member member = new Member(); //데이터베이스에서 조회한 회원 관련 정보를 모두 입력 Team team = new Team(); //데이터베이스에서 조회한 팀 관련 정보를 모두 입력 //회원과 팀 관계 설정 member.setTeam(team); return member; }근데 보통 객체와의 관계를 보면 위처럼 단순하지가 않다. 보통 여러 객체들 간의 관계들이 존재하는데 그 관계를 통하여 객체들을 자유롭게 참조를 이용하여 접근할 수 있지만 SQL에 따라 참조 범위가 결정이 된다. 즉, 실행하는 SQL에 따라 탐색 범위가 결정이 된다.


SQL에 따라 탐색 범위가 달라지기 때문에 엔티티 신뢰 문제가 생긴다. 해당 Member 객체에 참조된 객체들이 RDB에서 가져온 데이터가 저장되어있는지 직접적으로 알 수가 없게 된다. 이 말의 뜻은 직접적으로 참조된 객체들의 데이터가 저장되어있는지 확인해야 한다는 점이다.
class MemberService { ... public void process() { Member member = memberDAO.find(memberId); member.getTeam(); //??? member.getOrder().getDelivery(); // ??? } }그렇다고 Member 객체가 참조하는 모든 객체들을 미리 로딩하면 어떻게 될까? 심각한 리소스 낭비가 생긴다. 만약 Member와 Team과 관련된 정보만 사용한다면 다른 참조 관계에 있는 모든 테이블을 가져와서 사용하지도 않게 되기 때문에 연관관계에 있는 모든 객체들을 미리 로딩하는 방법은 좋은 방법이 아니다. 따라서 이 문제를 해결하기 위해서는 각 상황에 따라 동일한 객체 조회 메서드를 여러 번 작성해줘야 한다.
memberDAO.getMember(); //Member 조회 memberDAO.getMemberWithTeam(); //Member, Team 조회 memberDAO.getMemberWithOrderWithDelivery(); //Member, Order, Delivery 조회이렇듯 객체와 테이블의 차이점들로 인해 객체답게 모델링을 할수록 매핑 작업 등 여러 사항들을 고려해줘야 한다. 개발자들은 이러한 불편함을 해소하기 위해 객체를 자바 컬렉션에 저장하듯이 DB에 저장하고 싶어 하였고 그로 인해 등장하게 된 것이 JPA(Java Persistence API)이다.
728x90반응형'Spring > JPA' 카테고리의 다른 글
JPA - 연관관계 매핑 (0) 2022.03.08 JPA - 엔티티 매핑 (0) 2022.03.08 JPA - 영속성 컨텍스트 (0) 2022.03.07 JPA - JPA의 내부 동작과 Entity의 생명주기 (0) 2022.03.07 JPA - JPA(Java Persistence API) (0) 2022.03.07